
Mavors: Multi-granularity Video Representation for Multimodal Large Language Model
Abstract
Long-context video understanding in multimodal large language models (MLLMs) faces a critical challenge: balancing computational efficiency with the retention of fine-grained spatio-temporal patterns. Existing approaches (e.g., sparse sampling, dense sampling with low resolution, and token compression) suffer from significant information loss in temporal dynamics, spatial details, or subtle interactions, particularly in videos with complex motion or varying resolutions. To address this, we propose Mavors, a novel framework that introduces Multi-granularity video representation for holistic long-video modeling. Specifically, Mavors directly encodes raw video content into latent representations through two core components: 1) an Intra-chunk Vision Encoder (IVE) that preserves high-resolution spatial features via 3D convolutions and Vision Transformers, and 2) an Inter-chunk Feature Aggregator (IFA) that establishes temporal coherence across chunks using transformer-based dependency modeling with chunk-level rotary position encodings. Moreover, the framework unifies image and video understanding by treating images as single-frame videos via sub-image decomposition. Experiments across diverse benchmarks demonstrate Mavors' superiority in maintaining both spatial fidelity and temporal continuity, significantly outperforming existing methods in tasks requiring fine-grained spatio-temporal reasoning.
Teaser
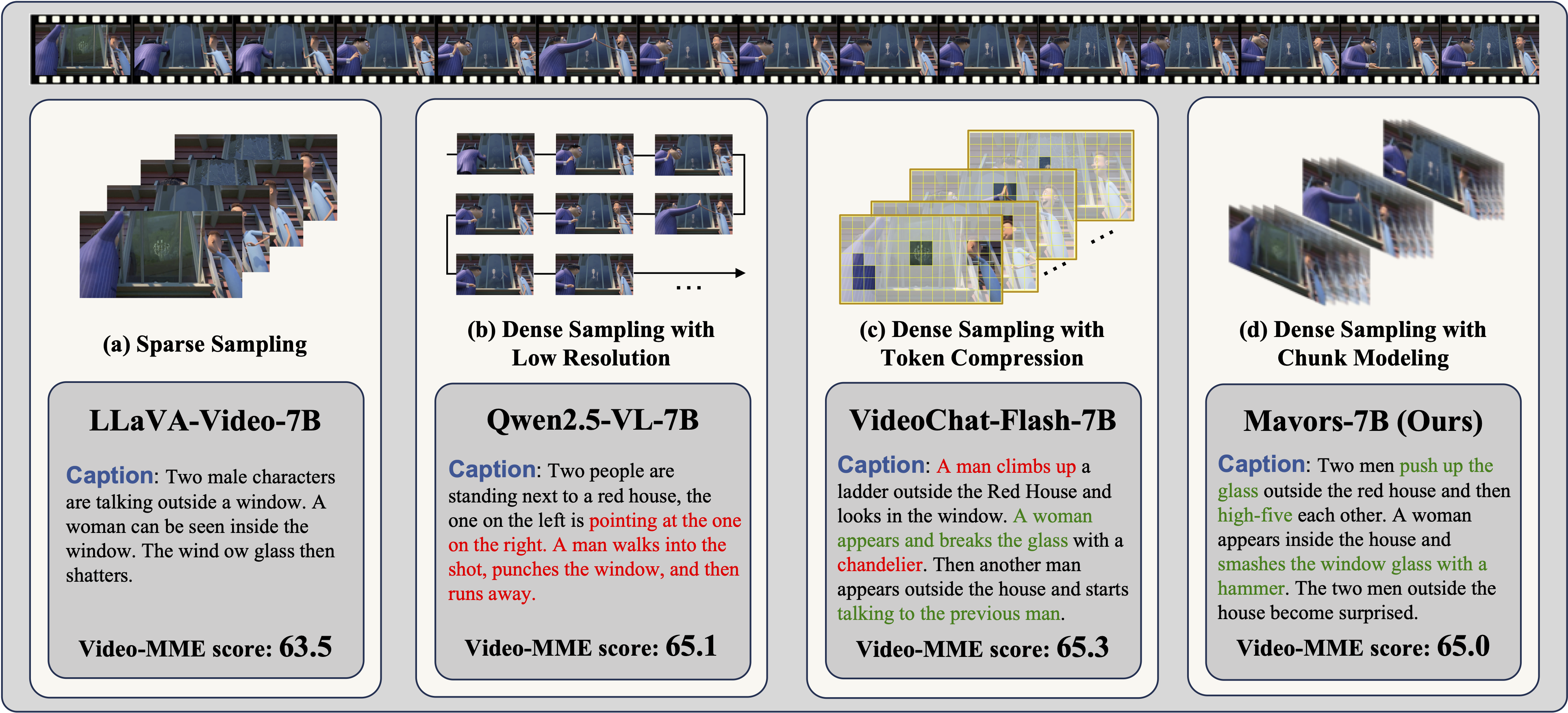
Existing video MLLMs struggle to balance computational efficiency with fine-grained spatial-temporal understanding. Sparse sampling drops crucial temporal cues, dense sampling with low-resolution lose spatial details, and token compression harms subtle motion and object interactions. To address this, we propose Mavors, a method that extracts Multi-granularity Video Representations, enabling MLLMs to retain spatial fidelity and temporal coherence across diverse video scenarios.
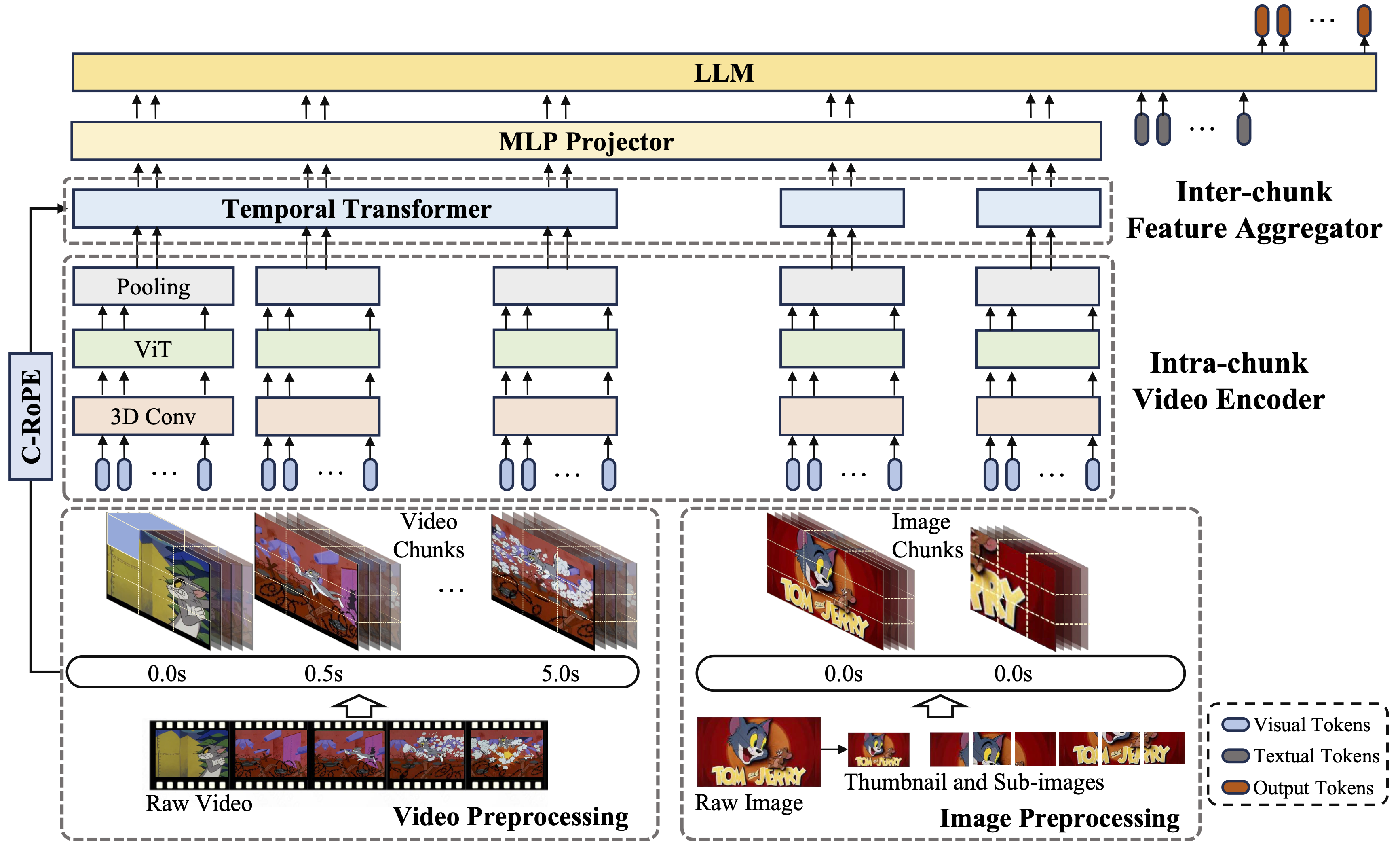
Model Architecture
Video Benchmark Performance
| Model | Size | MMWorld | PerceptionTest | Video-MME | MLVU | MVBench | EventHallusion | TempCompass | VinoGround | DREAM-1K |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o-20240806 | - | 62.5 | - | 71.9 | 64.6 | 64.6 | 92.0 | 73.8 | 38.9 | 39.2 |
| Gemini-1.5-Pro | - | - | - | 75.0 | - | 60.5 | 80.3 | 67.1 | 22.9 | 36.2 |
| LLaVA-OneVision | 7B | 59.2 | 56.9 | 58.9 | 64.8 | 56.7 | 64.3 | 61.4 | 26.2 | 31.9 |
| InternVL 2.5 | 8B | 62.2 | 65.0 | 64.3 | 67.0 | 72.0 | 64.1 | 71.4 | 24.0 | 29.7 |
| NVILA | 8B | 55.2 | 55.5 | 64.2 | 70.1 | 68.1 | 69.9 | 66.5 | 20.2 | 26.9 |
| LLaVA-Video | 7B | 60.1 | 67.5 | 63.6 | 67.2 | 58.6 | 70.7 | 65.7 | 26.9 | 33.3 |
| Oryx-1.5 | 7B | 58.8 | 70.3 | 59.0 | 63.8 | 67.5 | 61.3 | 60.2 | 22.3 | 32.5 |
| Qwen2.5-VL | 7B | 61.3 | 66.2 | 65.1 | 70.2 | 69.6 | 66.5 | 71.4 | 34.6 | 32.6 |
| VideoLLaMA3 | 7B | 56.4 | 72.8 | 66.2 | 73.0 | 69.7 | 63.4 | 68.1 | 31.3 | 30.5 |
| VideoChat-Flash | 7B | 57.9 | 74.7 | 65.3 | 74.7 | 74.0 | 66.4 | 70.0 | 33.3 | 29.5 |
| Slow-fast MLLM | 7B | 58.2 | 69.7 | 60.2 | 60.4 | 68.9 | 67.4 | 69.9 | 27.1 | 33.2 |
| Qwen2.5-VL | 72B | 73.1 | 73.2 | 73.3 | 76.6 | 70.4 | 76.3 | 79.1 | 58.6 | 35.1 |
| InternVL 2.5 | 78B | 77.2 | 73.5 | 72.1 | 76.6 | 76.4 | 67.7 | 75.5 | 38.7 | 30.3 |
| Mavors (Ours) | 7B | 68.1 | 70.3 | 65.0 | 69.8 | 68.0 | 73.5 | 77.4 | 36.9 | 39.4 |
Note: The best performance in each benchmark is highlighted in bold.
Image Benchmark Performance
| Model | Size | MMMU | MathVista | AI2D | CapsBench |
|---|---|---|---|---|---|
| GPT-4o-20240806 | - | 69.9 | 62.9 | 84.7 | 67.3 |
| Gemini-1.5-Pro | - | 60.6 | 58.3 | 79.1 | 71.2 |
| CogVLM2 | 8B | 42.6 | 38.7 | 73.4 | 50.9 |
| GLM-4V | 9B | 46.9 | 52.2 | 71.2 | 61.0 |
| LLaVA-OneVision | 7B | 47.9 | 62.6 | 82.4 | 57.4 |
| InternVL 2.5 | 8B | 56.2 | 64.5 | 84.6 | 66.5 |
| Qwen2.5-VL | 7B | 58.0 | 68.1 | 84.3 | 64.9 |
| DeepSeek-VL2 | 27B | 54.0 | 63.9 | 83.8 | 61.3 |
| Qwen2.5-VL | 72B | 68.2 | 74.2 | 88.5 | 70.1 |
| InternVL 2.5 | 78B | 70.0 | 70.6 | 89.1 | 68.5 |
| Mavors (Ours) | 7B | 53.2 | 69.2 | 84.3 | 75.2 |
Note: The best performance in each benchmark is highlighted in bold.
Citation
@misc{shi2025mavorsmultigranularityvideorepresentation,
title={Mavors: Multi-granularity Video Representation for Multimodal Large Language Model},
author={Yang Shi and Jiaheng Liu and Yushuo Guan and Zhenhua Wu and Yuanxing Zhang and Zihao Wang and Weihong Lin and Jingyun Hua and Zekun Wang and Xinlong Chen and Bohan Zeng and Wentao Zhang and Fuzheng Zhang and Wenjing Yang and Di Zhang},
year={2025},
eprint={2504.10068},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.10068},
}